ソースはこちら。
ロジック
RNNではよく「次の日の終値を予測する」といった記事を見かけますが、
実際のトレードではそのような予測は行いません。
実際のトレードでは必ずストップロスを設定するので、
たとえ終値が上昇していても日中下がってしまってストップロスに引っかかってしまったら意味がありません。
今回は「10pips下がる前に30pips上昇する」という条件をつけてエントリーポイントを学習できるかを考えます。
まずはデータを取得
こちらからEUR/USDの1分足データをダウンロードします。
そのデータを読み込み、シグナルを付与します。
シグナルは上述したとおりですが、より詳しく言うと、
- 対象は4時間(240分)。
- 下にnegative pips動く前に上にpositive pips動いていたら買い
- 上下にnegative pipsも動かなかった場合は凪
- 上にnegative pips動く前に上にpositive pips動いていたら売り
import pandas
positive_pips = 30
negative_pips = 10
point = 0.0001
# ファイルはここからダウンロードしている
# http://www.histdata.com/download-free-forex-historical-data/?/metatrader/1-minute-bar-quotes/EURUSD
df = pandas.read_csv('DAT_MT_EURUSD_M1_201706.csv',
names=['date', 'time', 'o', 'h', 'l', 'c', 'v'],
parse_dates={'datetime': ['date', 'time']},
) # type DataFrame
df.index = df['datetime']
# print(df[1707:1950])
df['signal'] = 0
print(len(df))
for i in range(len(df) - 241):
base = df.ix[i]
target = df[i:i + 240]
upper_negative = target.ix[target['h'] > df['h'][i] + negative_pips * point]
upper_positive = target.ix[target['h'] > df['h'][i] + positive_pips * point]
lower_negative = target.ix[target['l'] < df['l'][i] - negative_pips * point]
lower_positive = target.ix[target['l'] < df['l'][i] - positive_pips * point]
if len(upper_positive) > 0:
if len(lower_negative) == 0:
df['signal'][i] = 1
elif upper_positive.ix[0]['datetime'] < lower_negative.ix[0]['datetime']:
df['signal'][i] = 1
if len(lower_positive) > 0:
if len(upper_negative) == 0:
df['signal'][i] = -1
elif lower_positive.ix[0]['datetime'] < upper_negative.ix[0]['datetime']:
df['signal'][i] = -1
df.dropna()
df.to_csv('EURUSD_M1_201706_with_signal.csv')
訓練・検証データを吐き出す
ここから訓練・検証データを作ります。
1回の学習で使用する時系列データは1日分の1分足終値とします。
それを1時間ごとに取得してnumpyデータとして保存します。
import numpy
import pandas
df = pandas.read_csv('EURUSD_M1_201706_with_signal.csv')
df.drop('datetime', axis=1)
maxlen = 1440 # ひとつの時系列データの長さ(24時間)
x = numpy.empty((0, 1440), float)
y = numpy.empty((0, 1), int)
df.drop('v', axis=1)
signal = df['signal']
df.drop('signal', axis=1)
# 1時間ごとにトレーニングデータを作る
for i in range(1440, len(df), 60):
# とりあえず終値だけにしてみる
append_x = numpy.array([df['c'].ix[i - maxlen: i - 1]])
append_y = numpy.array([0, 0, 0])
# 1-of-K 表現に変換
if signal.ix[i] < 0:
append_y[0] = 1
elif signal.ix[i] > 0:
append_y[2] = 1
else:
append_y[1] = 1
x = numpy.append(x, append_x)
y = numpy.append(y, append_y)
numpy.save('EURUSD_M1_201706_x.npy', x)
numpy.save('EURUSD_M1_201706_y.npy', y)
学習・検証を行う
学習を行います。
ロジックはGRUを用い、勾配降下法はAdamで最適化します。
import numpy
from keras.callbacks import EarlyStopping, TensorBoard
from keras.layers import GRU, Dense, Activation
from keras.models import Sequential
from keras.optimizers import Adam
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
def weight_variable(shape, name=None):
return numpy.random.normal(scale=.01, size=shape)
maxlen = 1440 # ひとつの時系列データの長さ(24時間)
x = numpy.load('EURUSD_M1_201706_x.npy')
y = numpy.load('EURUSD_M1_201706_y.npy')
# 正規化
x = x / numpy.linalg.norm(x)
x = x.reshape((int(len(x) / maxlen), maxlen, 1))
y = y.reshape((len(x), 3))
X_train, X_test, Y_train, Y_test = train_test_split(x, y, train_size=0.8)
X_train, X_validation, Y_train, Y_validation = \
train_test_split(X_train, Y_train, train_size=0.8)
n_in = len(x[0][0]) # 1
n_hidden = 16
n_out = len(y[0]) # 3
epochs = 10
batch_size = 10
early_stopping = EarlyStopping(monitor='loss', patience=100, verbose=1)
model = Sequential()
model.add(GRU(n_hidden,
kernel_initializer=weight_variable,
input_shape=(maxlen, n_in)))
model.add(Dense(n_out))
model.add(Activation('softmax'))
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
model.compile(loss='categorical_crossentropy',
optimizer=optimizer)
hist = model.fit(X_train, Y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_validation, Y_validation),
callbacks=[early_stopping, TensorBoard(log_dir="log", histogram_freq=1)])
'''
予測精度の評価
'''
loss_and_metrics = model.evaluate(X_test, Y_test)
print(loss_and_metrics)
実行結果
C:\Users\tono\Anaconda3\python.exe C:/Users/tono/Python/keras-fx/predict_rnn.py
Using TensorFlow backend.
Train on 316 samples, validate on 80 samples
Epoch 1/10
...
290/316 [==========================>...] - ETA: 4s - loss: 0.5638
300/316 [===========================>..] - ETA: 2s - loss: 0.5605
310/316 [============================>.] - ETA: 1s - loss: 0.5636Traceback (most recent call last):
316/316 [==============================] - 59s - loss: 0.5627 - val_loss: 0.5350
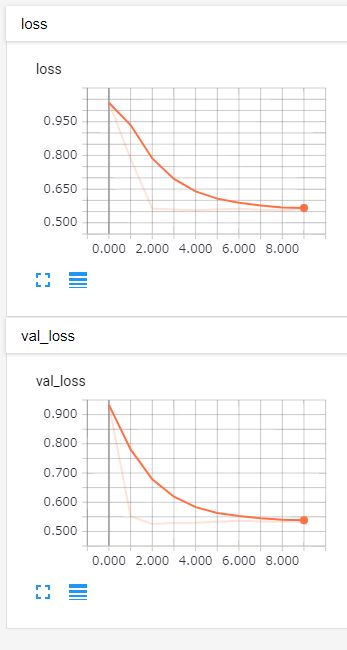
一応もっとエポック数多いものも試しましたが、
0.5台から下がりませんでした。
損失関数の指定が難しい
今回は正解ラベルを買い・凪・売りの1-of-K表現にしていましたが、
正解ラベルがほとんど0であるということと、凪のときに売買して10pipsの損切りにあったかあわなかったかが全く考慮されていないというのが問題です。
ここらへんが考慮できる高速な損失関数の設定はできないかもしれないですね…
ここまでやるなら強化学習?
そこまで詳細に損益計算をしなければならないのであれば、
損益を報酬とした強化学習を行ったほうがいいのではないかと思えてきました。
というわけで、次回は強化学習で実装してみようと思います。


コメント